期刊:IEEE Transactions on Circuits and Systems for Video Technology,2023
作者:王岚晓;邱荷茜;邱奔流;孟凡满;吴庆波;李宏亮
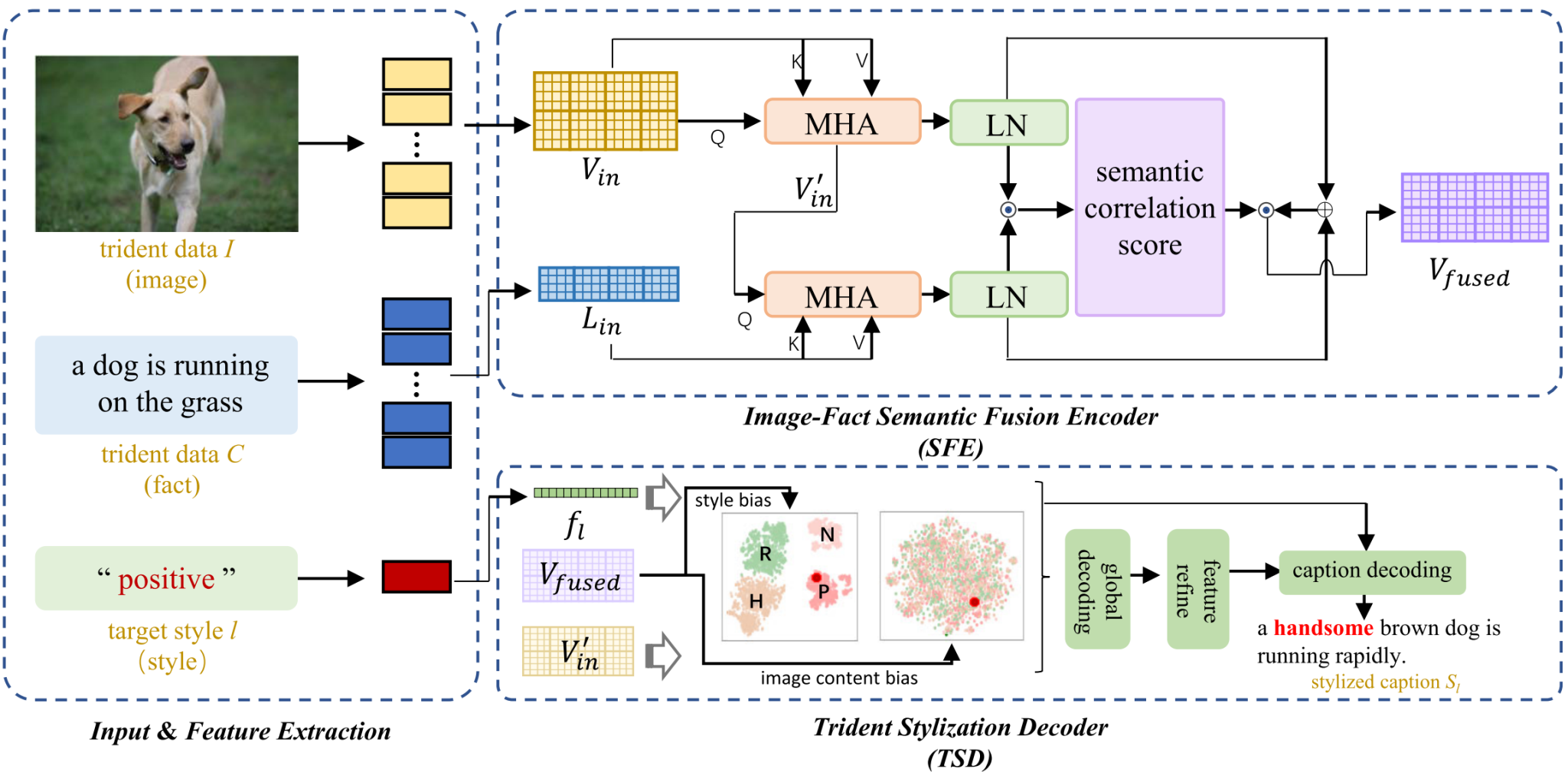
论文简介:风格化图像描述(SIC)的目标是为图像生成具有目标风格的描述。最大的挑战在于收集和标注风格化数据既困难又耗时。大多数现有方法独立地学习大量的事实性描述或额外的风格化书籍语料库,以辅助生成风格化描述,却忽略了现有图像-事实-风格三叉戟数据之间的核心关系。在本文中,该论文提出了一种新颖的图像-事实-风格三叉戟语义框架TridentCap,用于风格化图像描述,该框架包括一个图像-事实语义融合编码器(SFE)和一个三叉戟风格化解码器(TSD)。与现有方法不同,该论文直接挖掘图像-事实-风格三叉戟数据中的核心关系,并利用事实语义和图像构建跨模态语义特征空间,实现图像与文本之间的一致性。具体来说,SFE旨在从事实性文本中学习与图像相关的先验语言知识信息,并利用图像和事实性文本之间的细粒度区域级语义相关性来实现跨模态语义信息的对齐和融合。TSD旨在根据目标风格对双源融合语义特征进行解耦,以实现风格化描述的生成。此外,该论文还设计了一个伪标签过滤器(PLF),通过为传统描述数据集中的所有图像-事实数据构建伪风格化标注,来获得和扩展大量的图像-事实-风格三叉戟数据,这可以进一步加强风格化描述的学习。这是一种通用的算法,用于解决数据不足的问题,并可应用于任何现有的风格化描述模型。该论文在SentiCap和FlickrStyle数据集上进行了广泛的实验,几乎所有指标均取得了持续改进。