会议:ACM MM 2022
作者:邱荷茜,李宏亮,赵泰锦,王岚晓,吴庆波,孟凡满
论文简介:
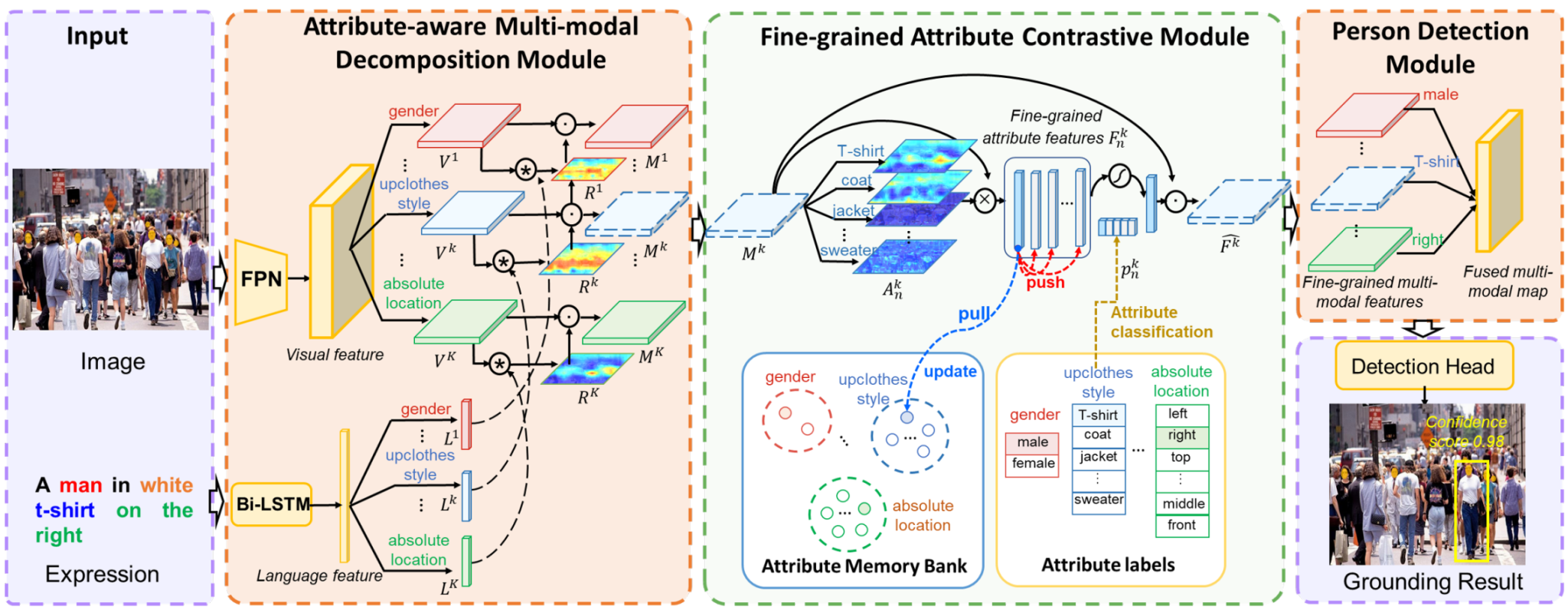
人群理解因其重要的实际意义而在视觉领域引起了广泛关注。然而,尚未有工作在多模态领域中探讨将自然语言与计算机视觉相结合的人群理解。指代表达理解(REF)是这样一种具有代表性的多模态任务。目前的REF研究主要集中在一般场景中从多个不同类别中定位目标对象,但这在复杂的现实世界人群理解中难以应用。为填补这一空白,该论文提出了一个新的具有挑战性的数据集,称为RefCrowd,该数据集旨在通过指代表达寻找人群中的目标人物。这不仅要求充分挖掘自然语言信息,还要求仔细关注目标与外貌相似的人群之间的细微差别,从而实现从语言到视觉的细粒度映射。此外,该论文提出了一种细粒度多模态属性对比网络(FMAC),以解决人群理解中的REF问题。该网络首先将复杂的视觉和语言特征分解为属性感知的多模态特征,然后捕捉具有辨别力但具有鲁棒性的细粒度属性特征,以有效区分相似人物之间的这些细微差别。所提出的方法在我们的RefCrowd数据集和现有的REF数据集上均优于现有的最先进方法(SoTA)。此外,该论文实现了一个端到端的REF工具箱,以促进多模态领域的深入研究。