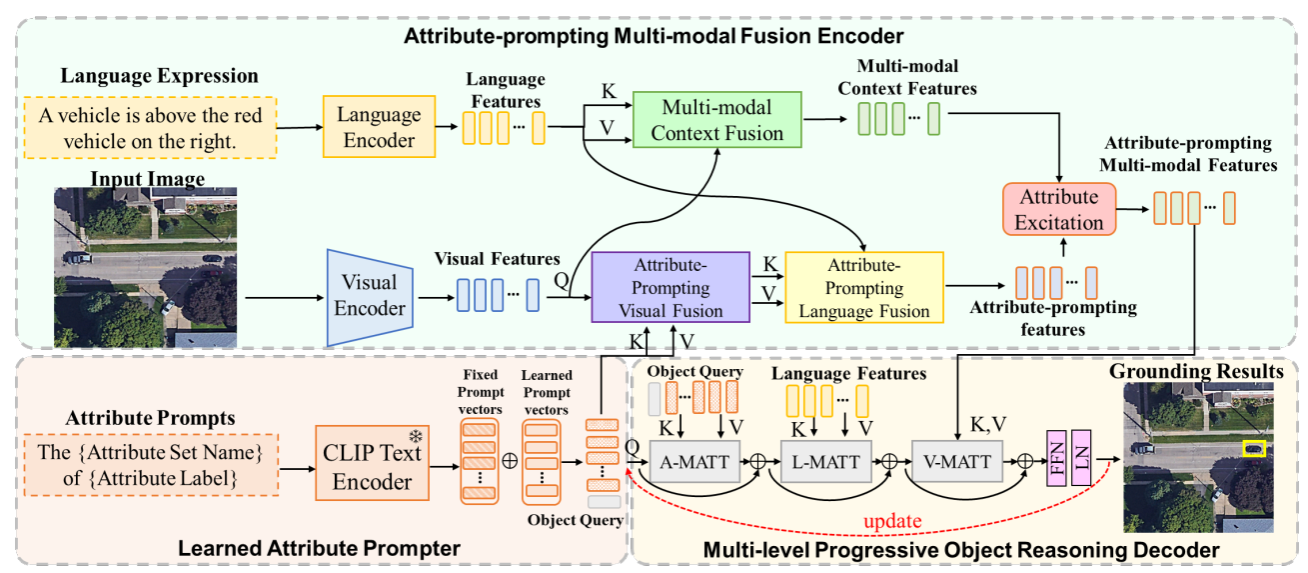
以团队师资博后邱荷茜为第一作者,李宏亮教授和王岚晓博士为通讯作者共同完成的研究论文《Attribute-prompting Multi-modal Object Reasoning Transformer for Remote Sensing Visual Grounding》被IEEE国际地球科学与遥感大会(IGARSS 2024)会议接收。遥感视觉定位任务旨在遥感图像中定位出自然语言表达描述的特定目标对象,要求精准地对齐和融合不同模态的特征。然而,现有方法通常采用目标区级级的多模态融合,严重限制了遥感图像中目标细节特征的捕获,导致相似目标间的混淆问题。为了解决上述问题,该论文提出了一个属性提示的多模态目标推理网络。该网络首先设计了一个可学习的属性提示器,通过根据遥感图像公共的目标对象特征,以自适应挖掘多样且丰富的属性信息。借助于这些属性提示,提出一个属性提示的多模态融合编码器以建立视觉和语言特征间细粒度的交互对齐,从而避免目标混淆。进一步地,一个多模态渐进式目标推理解码器逐步查询更综合全面的目标特征,以实现精准的目标定位。实验结果验证了本文方法的有效性。
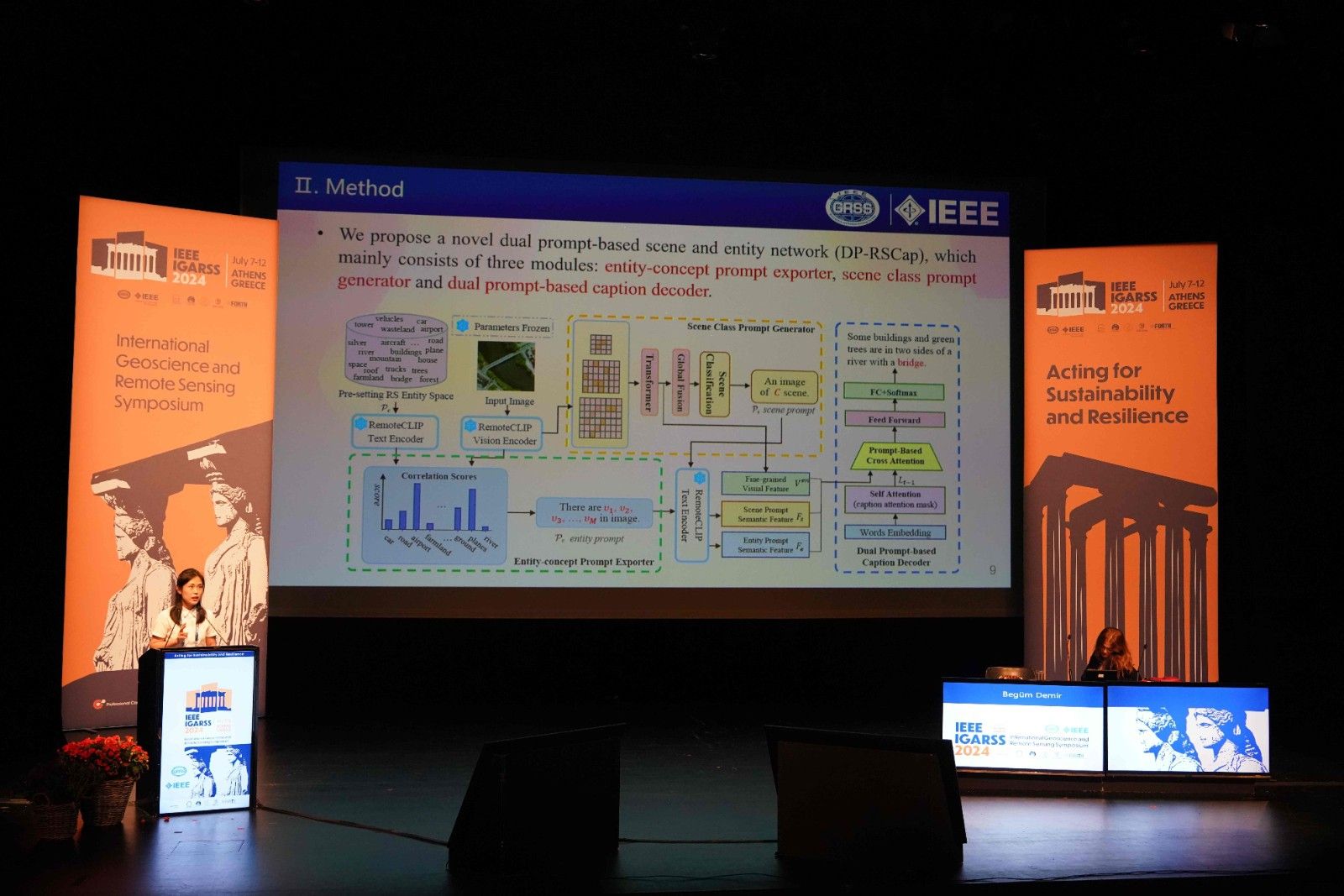
以王岚晓博士为第一作者,李宏亮教授和邱荷茜博士为通讯作者共同完成的研究论文《Dual Prompt-Based Scene and Entity Network for Remote Sensing Image Captioning》被IGARSS 2024接收并进行口头汇报。多模态遥感视觉描述生成任务的目的是理解图像场景内容,按照人类的语言规则,利用自然语言进行描述。然而,遥感图像具有背景复杂、目标密集等特点,这使得实现充分的视觉语义信息提取和精确的视觉-文本模态映射变得更加具有挑战性。因此,该论文旨在充分利用预训练模型强大的泛化能力提升遥感视觉描述生成性能,提出了场景-对象双提示的遥感视觉描述生成模型(DP-RSCap)。该网络通过设计场景提示和对象提示,挖掘文本先验信息,作为一种显式的中间连接,辅助视觉-文本语义映射。该先验信息不仅与视觉模态内容相匹配,而且与文本模态特征空间相匹配。从而在解码过程中构建跨模态映射的桥梁,实现更精准的描述生成。