期刊:IEEE Transactions on Multimedia,2023
作者:王岚晓;李宏亮;张敏健;邱荷茜;孟凡满;吴庆波;许林峰
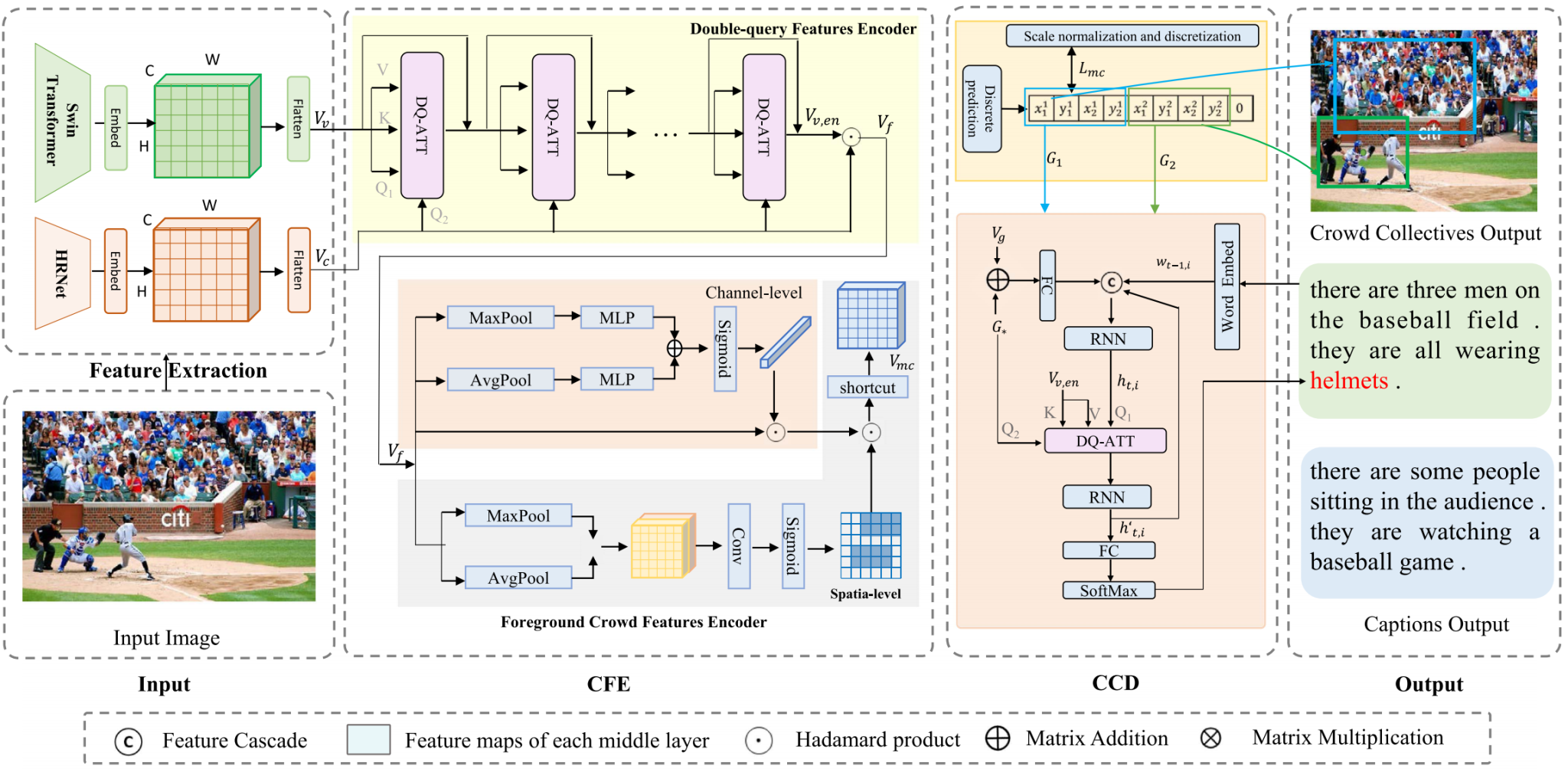
论文简介:人群场景分析在公共安全、智慧城市和智能交通系统等多个领域发挥着重要作用。然而,传统的人群场景描述方法主要关注单一且显著的人群集体,这限制了它们在复杂人群场景中描述不同人群集体的能力。为了解决这个问题,该论文提出了一种集体引导的人群场景描述模型(CrowdCaption++),以探索更全面、更详细的描述。该论文设计了一个人群特征编码器(CFE),包括双查询特征编码器和前景人群特征编码器,该编码器利用双查询注意力模块(DQ-ATT)捕获更具代表性的视觉特征,并提取前景人群特征以避免背景对集体预测的干扰。此外,该论文构建了一个集体引导的描述解码器(CCD),以生成不同人群集体的描述,而无需在人群集体和描述之间进行额外的对齐。为实现这一目标,该论文首先设计了一个人群集体预测器来识别多个潜在的人群集体,并创建人群集体引导信息。最后,该论文使用人群集体引导信息来合并有用的视觉特征,并进一步生成相应的描述。该论文在最新的人群场景数据集CrowdCaption上评估了该论文的方法,并证明该论文的模型能够实现对复杂人群场景中不同人群集体的全面理解和描述。