会议:CVPR 2024
作者:邱子欢,徐易,孟凡满,李宏亮,许林峰,吴庆波
论文简介:
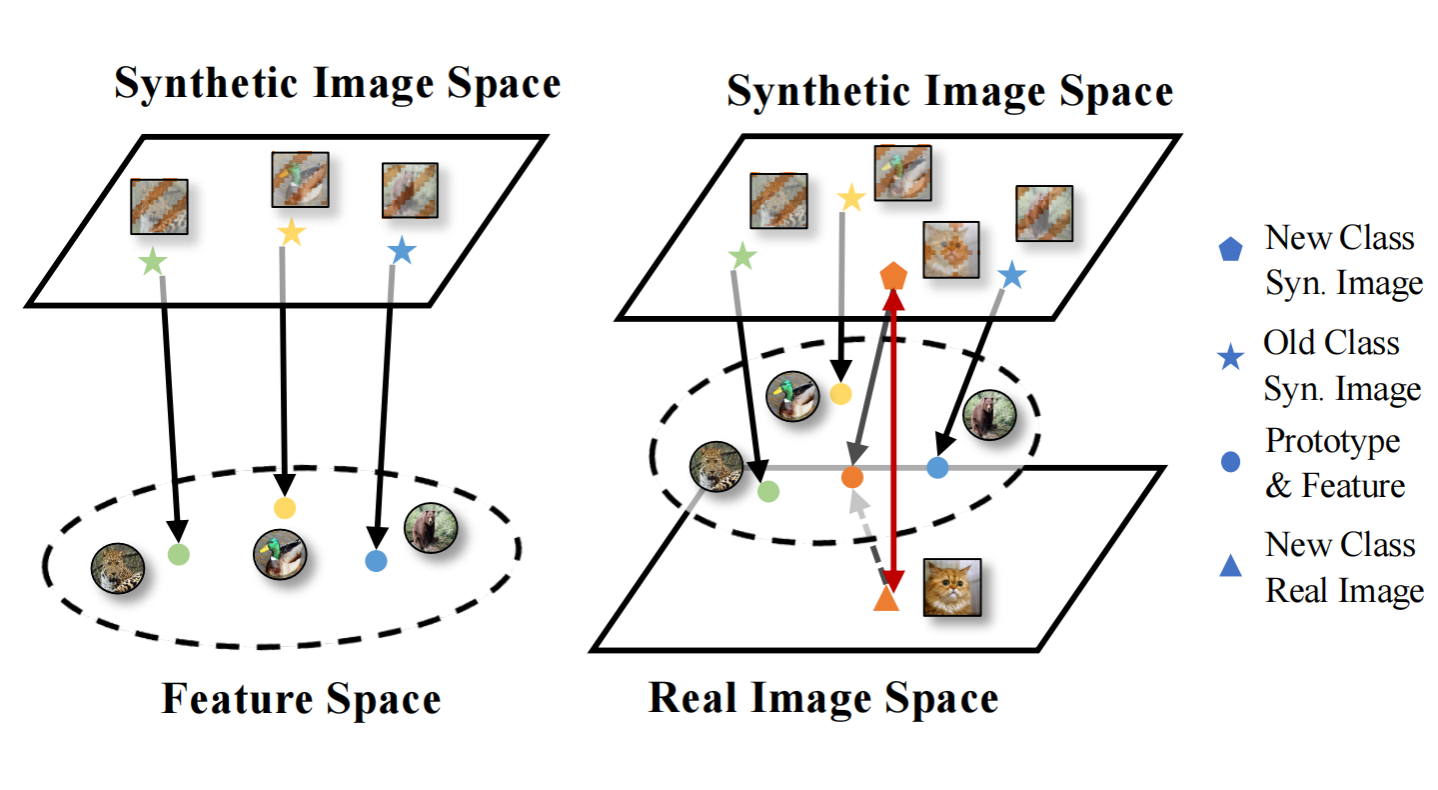
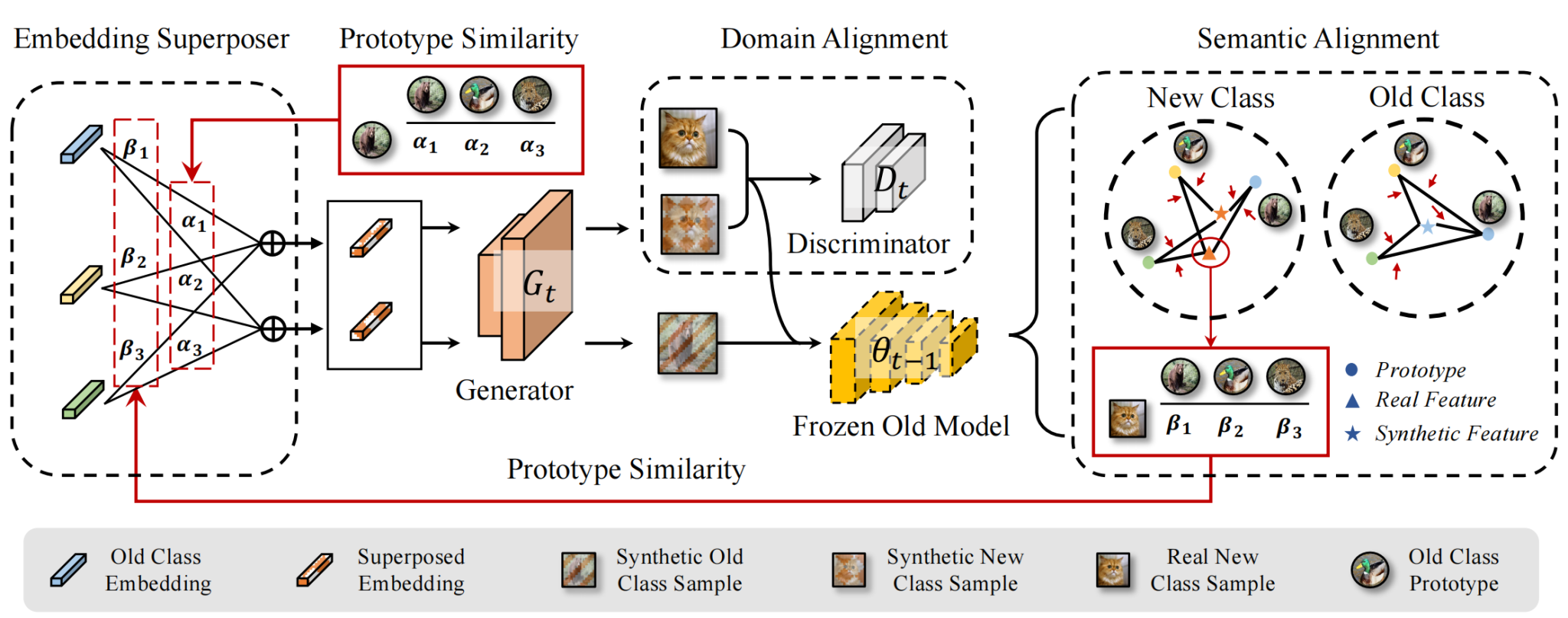
深度模型的增量学习能力至关重要。传统类增量学习要求保存部分旧类别样本,导致数据隐私,版权以及存储等问题。无模范的类增量学习无需进行回放学习,但更加容易发生灾难性遗忘。目前无模范类增量学习主要采用知识蒸馏巩固旧类表示,使用新类别样本或反演样本作为蒸馏数据。然而,前者与旧类分布具有语义差异,后者在领域分布上与真实样本缺乏一致。为生成更有效的蒸馏数据,本文提出双一致性模型反演方法DCMI,使生成数据在语义和领域分布上与真实旧类分布更加一致。实验表明,DCMI在无模范类增量学习基准下取得了最先进的性能。