会议:CVPR 2023
作者:邱奔流;李宏亮;问海涛;邱荷茜;王岚晓;孟凡满;吴庆波;潘力立
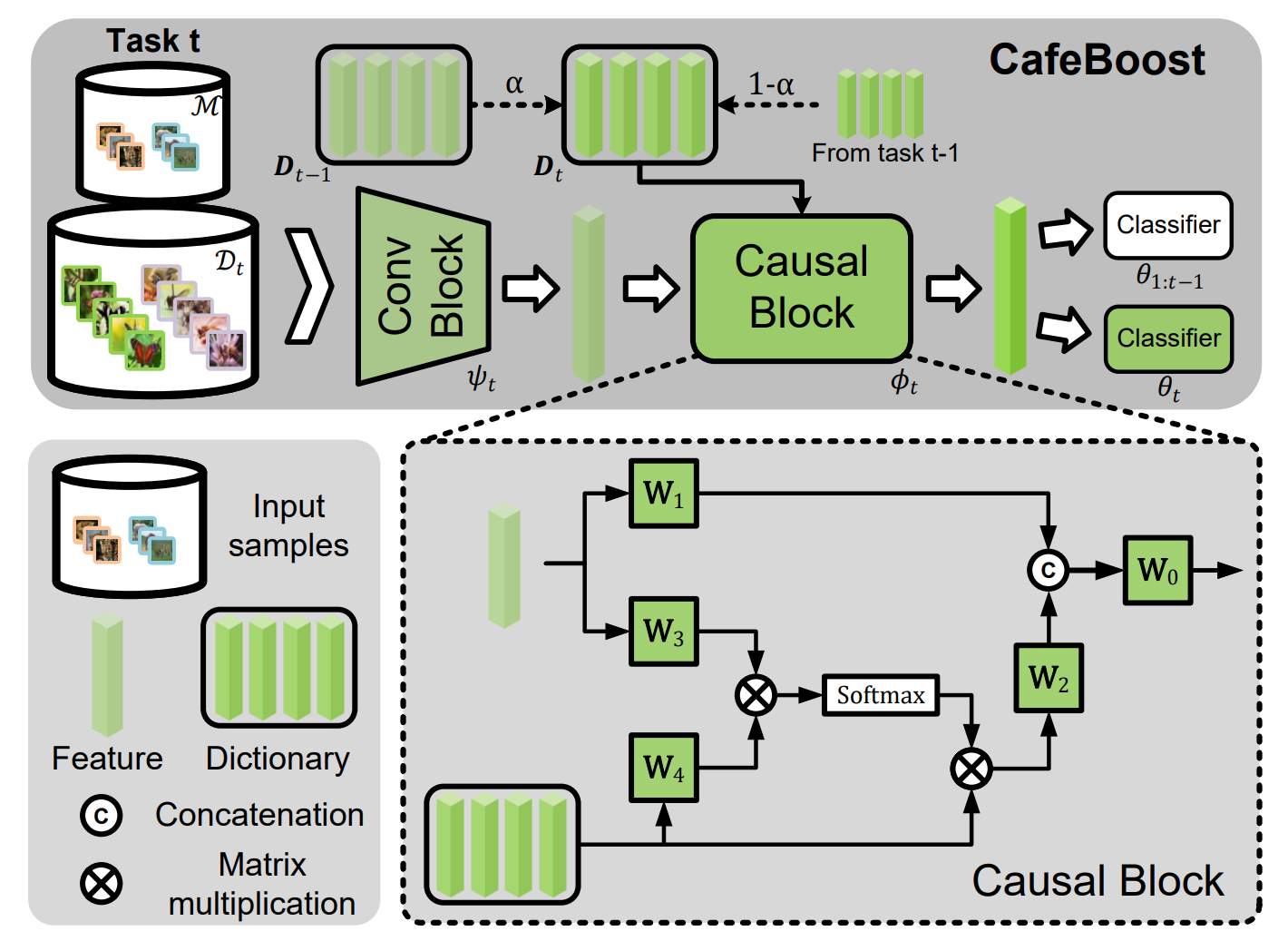
论文简介:持续学习需要一个模型来增量地学习一系列任务,并旨在预测到目前为止所学到的所有任务,这是众所周知的灾难性遗忘问题。在本文中,我们发现了一种新的偏差出现在持续学习中,被称为任务诱导偏差。我们将持续学习置于一个因果框架中,在此基础上,我们发现任务诱发的偏见在任务和领域增量学习中的两种潜在机制下自然减少。然而,在类增量学习(CIL)中不存在这些机制,其中每个任务包含一个唯一的类子集。为了消除CIL中的任务诱导偏倚,我们设计了一个因果干预操作,切断导致任务诱导偏倚的因果路径,然后将其作为一个将有偏特征转换为无偏特征的因果去偏模块来实现。此外,我们提出了一个培训管道,将新模块整合到现有方法中,共同优化整个体系结构。我们的总体方法不依赖于数据回放,并且简单方便地插入现有方法。对CIFAR-100和ImageNet的大量实证研究表明,我们的方法可以提高准确率,并大大减少已建立方法的遗忘。