期刊:IEEE Transactions on Circuits and Systems for Video Technology,2023
作者:尚超;李宏亮;邱荷茜;吴庆波;孟凡满;赵泰锦;颜庆义
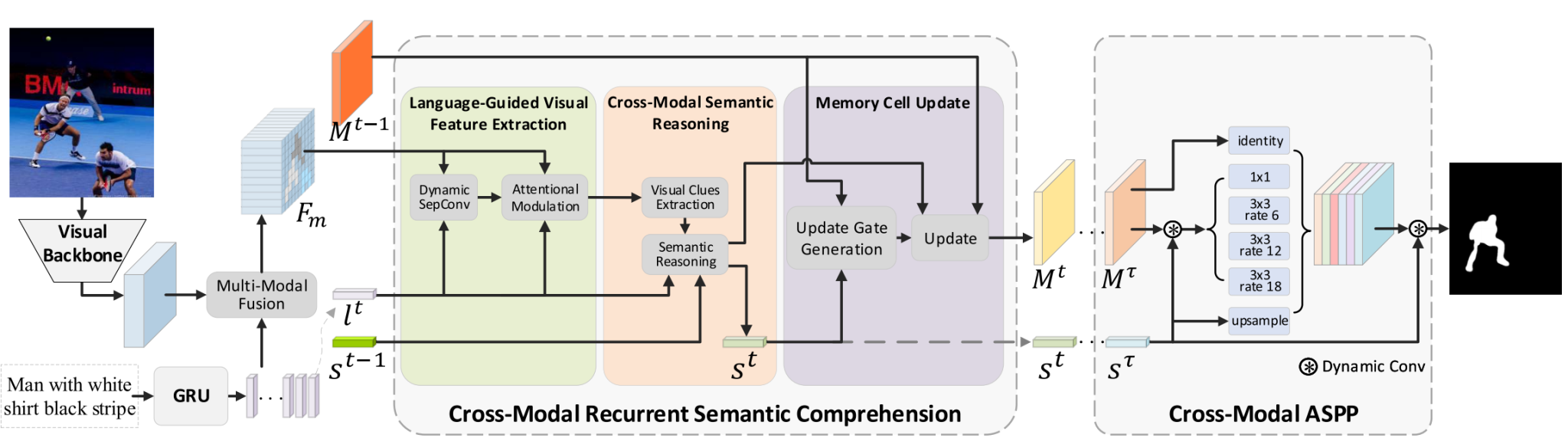
论文简介:指代图像分割旨在根据语言表达的描述从图像中分割出目标对象。由于语言表达的多样性,不同顺序的词序列往往表达不同的语义信息。以前的方法更多地关注于将不同的单词分别与图像中的不同视觉区域进行匹配,而忽略了基于序列结构的语言表达的全局语义理解。为了解决这个问题,该论文为指代图像分割重新设计了一种新的循环网络结构,称为跨模态循环语义理解网络(CRSCNet),通过迭代跨模态语义推理来获得更全面的全局语义理解。具体来说,在每个迭代中,该论文首先提出了一种动态分离卷积(Dynamic SepConv),以语言为指导提取相关视觉特征,并进一步提出了语言注意力特征调制(Language Attentional Feature Modulation)以提高特征的判别力。然后,该论文提出了一个跨模态语义推理模块,通过捕获语言和视觉信息来进行全局语义推理,并最终根据语义信息更新和校正预测对象的视觉特征。此外,该论文还进一步提出了跨模态ASPP(Atrous Spatial Pyramid Pooling,空洞空间金字塔池化),以从更大的感受野中捕获语言表达全局语义中提到的更丰富的视觉信息。大量实验表明,该论文提出的网络在多个数据集上的表现显著优于之前的最先进方法。